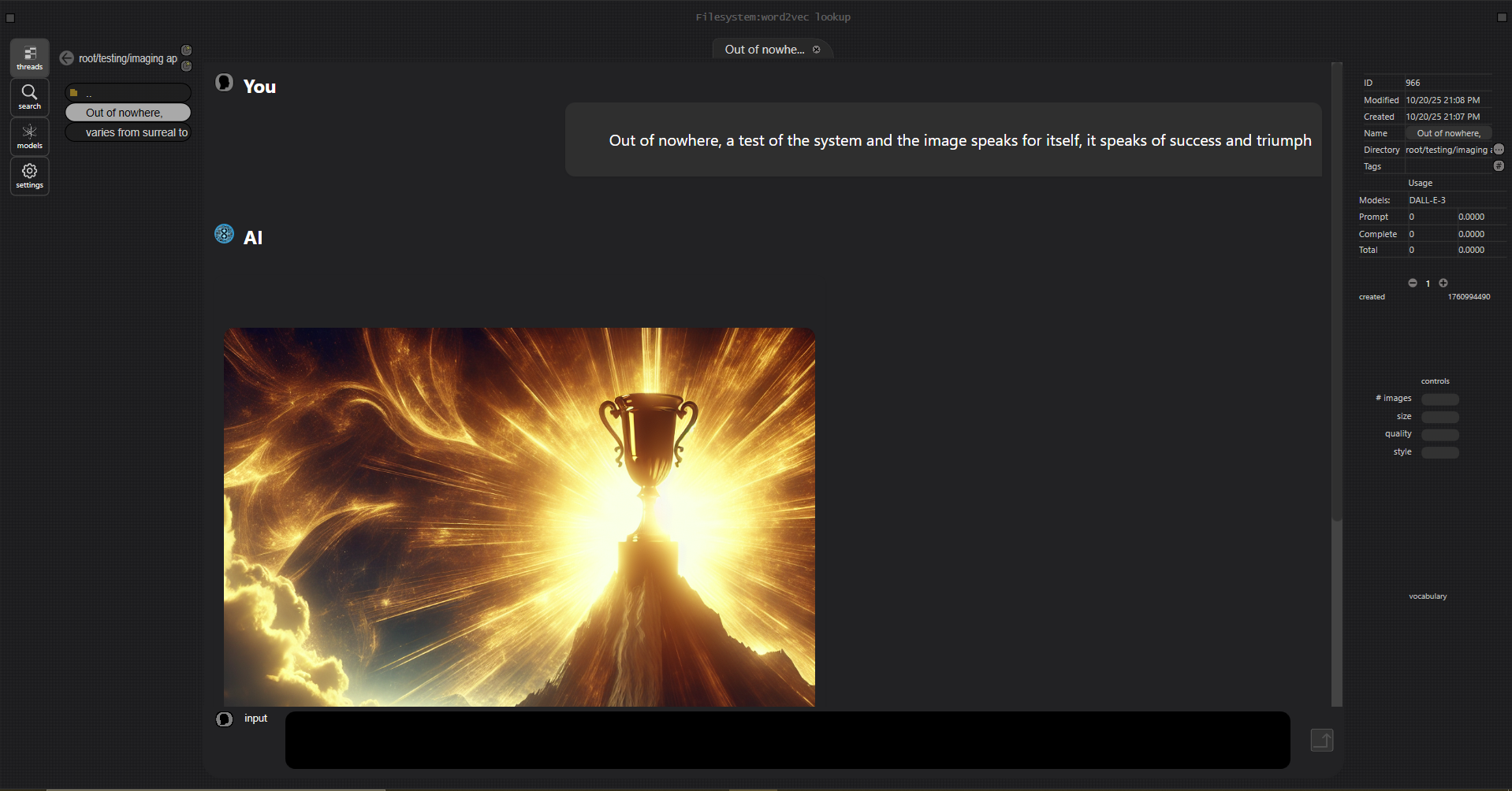

I've been working with embeddings a lot the last few months. I got really intrigued by some of those old "king/queen" videos and wanted to see if the gpt embeddings showed the same properties.
Endpoint: v1/embeddings
Models: text-embedding-ada-002, text-embedding-3-small, text-embedding-3-large
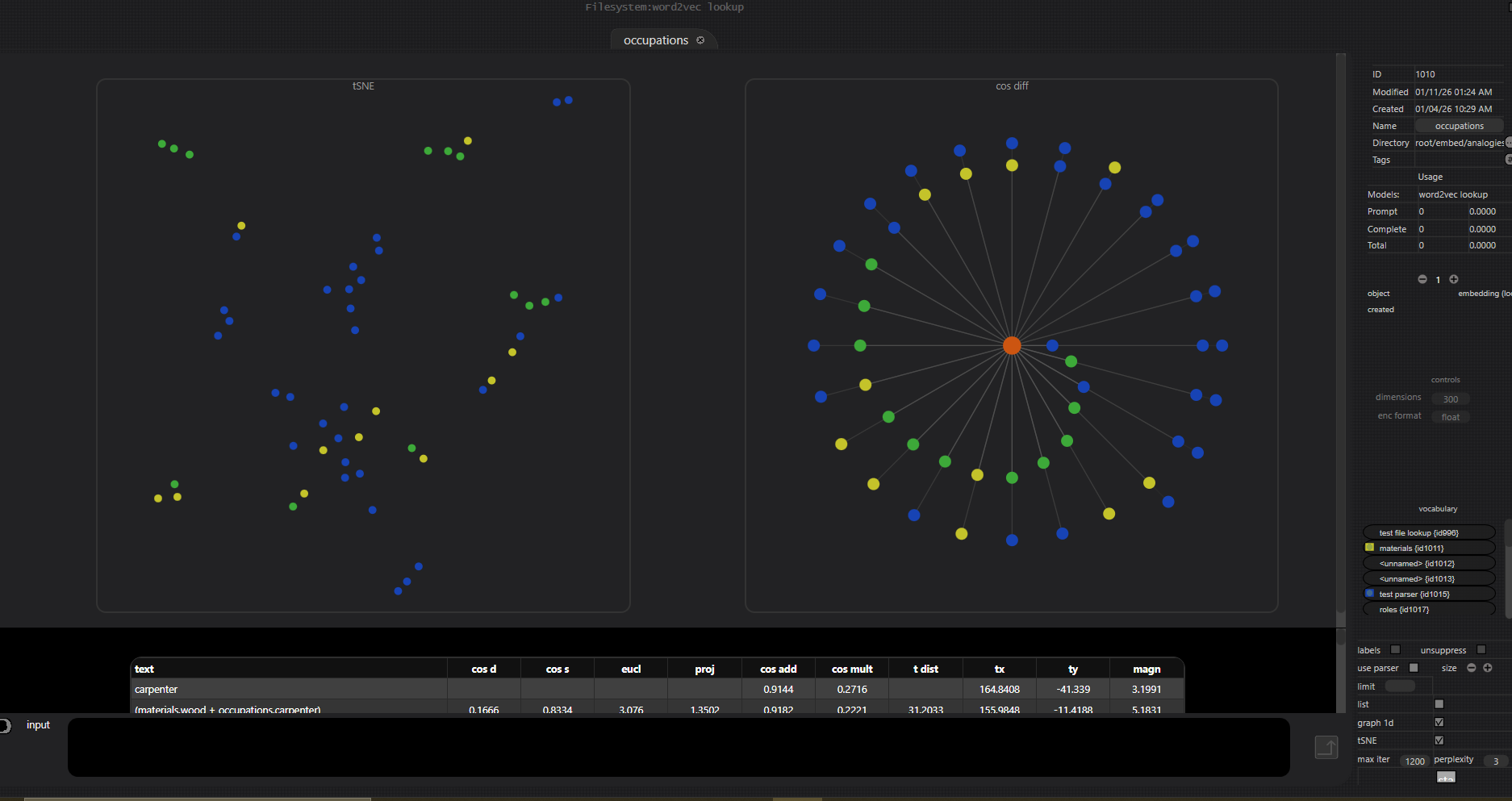
Those old gensim videos showed how vector arithmetic could produce something like a semantic transformation when working with word2vec and glove embeddings. To reproduce with gpt embeddings, the software I've written has a fairly extensive set of vector operations: normalize, dot product, 7D curl (IYKYK), etc...
I've implemented a data reduction feature using tSNE. Mulling over adding umap.
Mostly, I am interested in operating on blocks of texts, but to test my setup I wanted to reproduce what I'd seen with the word2vec embeddings.
This software will read the text and binary files like those in the nlpl repository (http://vectors.nlpl.eu/repository), which are the only ones I've used. Currently, embeddings are read from the file on-demand and put into a database. The idea here is that relatively few embeddings will be of interest and once in the database, there is no need to spend time parsing the file.
Nearest neighbors are only among those embeddings in the database, unlike with gensim which provides a list of the top 5 or 10 closest matches in the entire vocabulary. Such a thing has no applicability when using the OpenAi embeddings api with blocks of text but I still think it would be nice to have so I will probably implement some kind of FAISS/ANN scheme.
I am releasing a version of the software that works with the nlpl files (http://vectors.nlpl.eu/repository), even though feature-wise it lags behind gensim for the target data. But if you want to play around with that data and don't want to deal with Python, you are welcome to use it.
Most of what I've done was with the GoogleNews-vectors-negative300.bin file and the English CoNLL17 corpus embeddings.